개요
지도 학습에 속하는 Regression과 Classification 중 Classification의 범주에 들어가는,
Logistic regression에 대해 알아보았다.
우리는 보통 우리에게 주어진 task를 해결하기 위해 아래와 같은 과정을 겪게 된다고 한다.
- 다양한 모델 중에서 한 가지를 선택
- 다양한 cost function 중에서 한 가지를 선택
- gradient descent 과정을 진행
- 최적의 가중치 획득
이 과정에서 우리는 스팸 메일, 악성 종양 등의 분류를 위해 classification의 logistic regression model을 택했다.
이제 cost function에 대해 알아볼 시간이다.
Linear regression에서 만났던 cost function
Linear regression에서의 target variable은 연속된 값을 예측하는 것이었다.
즉, classification에서와는 달리 regression에서는 연속된 값을 예측하는 것이 task이다.
그래서 가설을 설정할 때,
y = ax + b
이런 꼴의 가설을 설정했고 hypothesis의 결과로 나오는 값의 범위가 아래와 같았다.
-∞ <= hθ(x) <= ∞
그리고 우리는 이러한 가설 아래에서 cost function으로 Mean square error, mean absolute error와 같은
cost function을 사용했다.
하지만 classification에서는 이를 적용할 수가 없다.

y hat이 예측값, y가 실제값
둘이 자리를 바꿔도 상관 없다.
Cost function for Logisitic regression
위를 적용할 수 없는 이유는 가설값으로 도출되어야 하는 값의 범위가 아래와 같이 제한되어야 한다.
0 <= hθ(x) <= 1
이유는 당연히 negative case는 0으로 positive case는 1로 분류하기 위해서이다!
그래서 우리는 cost function을 통해 실제값이 1에 해당할 때,
우리의 예측값이 1에 가까울 수록 cost는 0에 수렴하고
0에 가까울 수록 cost는 무한대로 발산하도록 만들어주어야 한다.
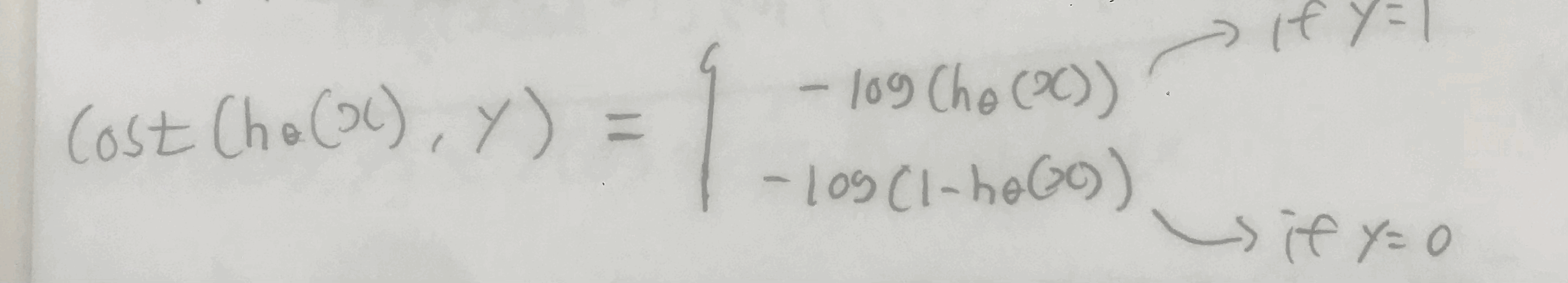
실제값이 1일 때, 위의 함수를 적용해주면 되고
실제값이 0일 때, 아래의 함수를 적용해주면 된다.
이 cost function을 그래프로 나타낸 모습은 아래와 같다. (실제값이 1인 경우의 함수를 썼을 때 로그 그래프)
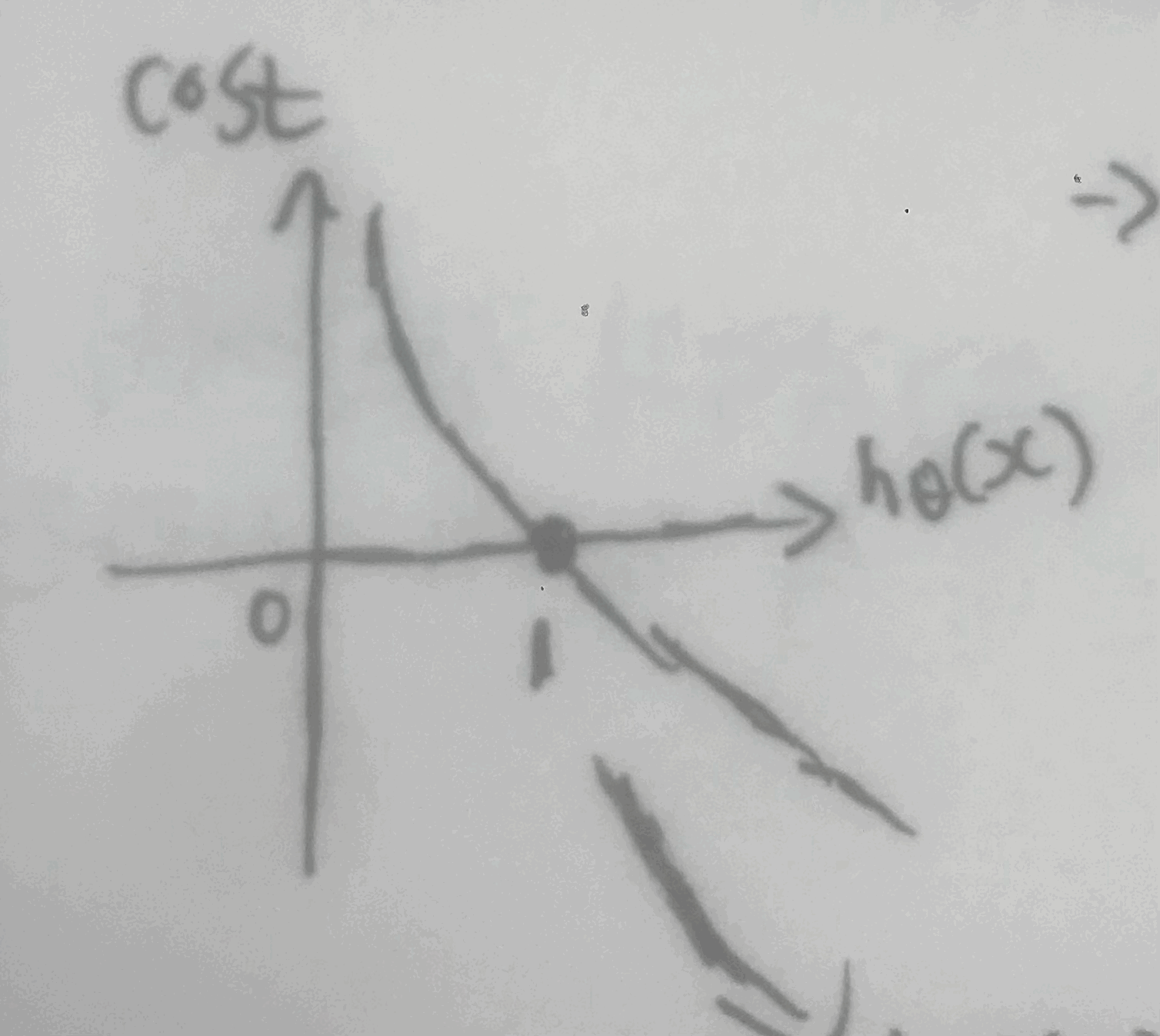
예측값이 1에 가까워질 수록 cost가 0에 수렴되는 모습을 볼 수 있다!
실제값이 0인 경우의 함수를 썼을 때 로그 그래프는 아래와 같다.
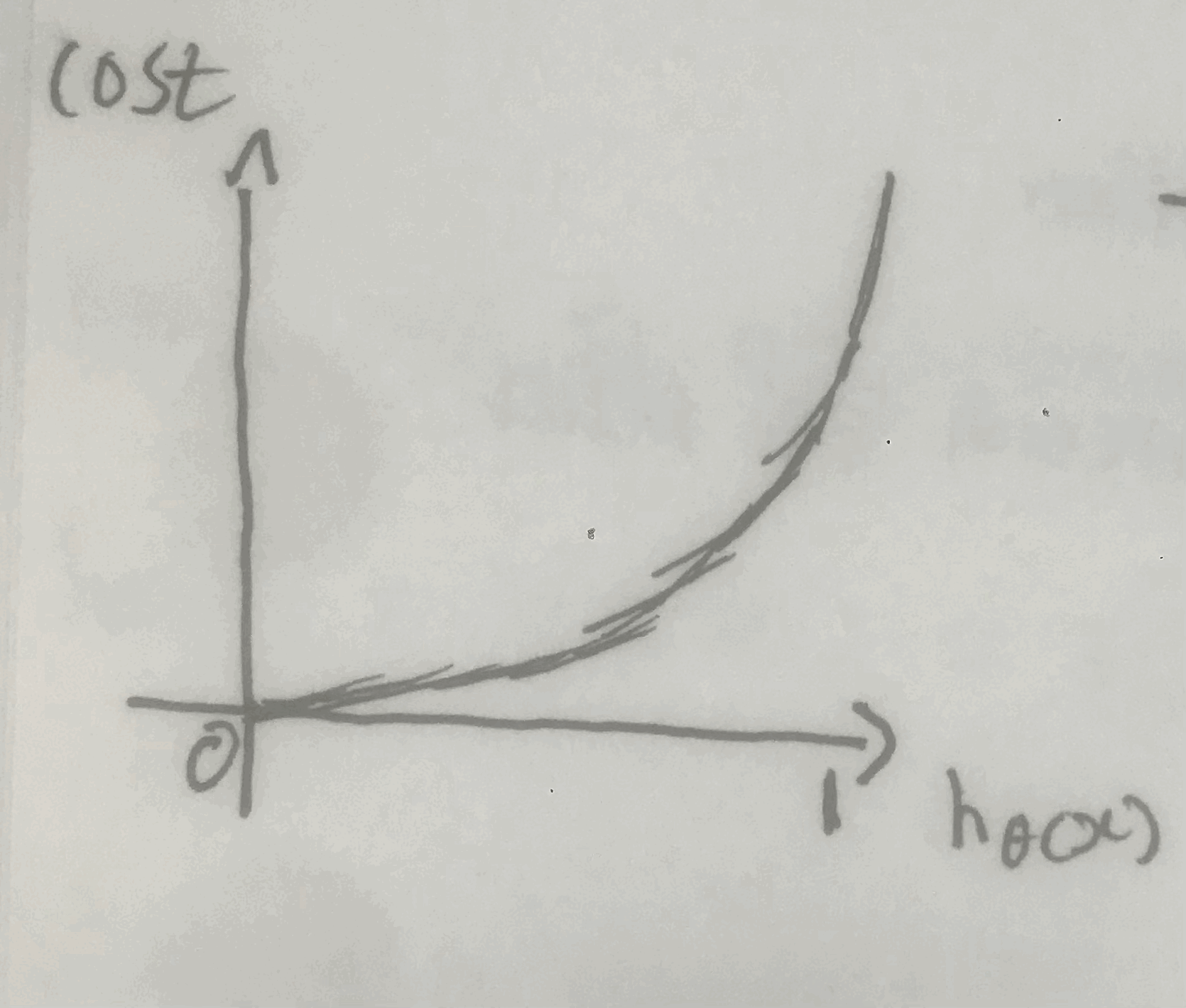
예측값이 0에 가까워질 수록 cost가 0에 수렴되는 모습을 볼 수 있다!
한 줄로 Logistic regression의 cost function 나타내기

이게 가능한 이유는,
y = 1이면 뒤에 있는 식이 사라지고
y = 0이면 앞에 있는 식이 사라진다.
결과적으로 아래와 같이 mean error function으로 나타낼 수 있다.
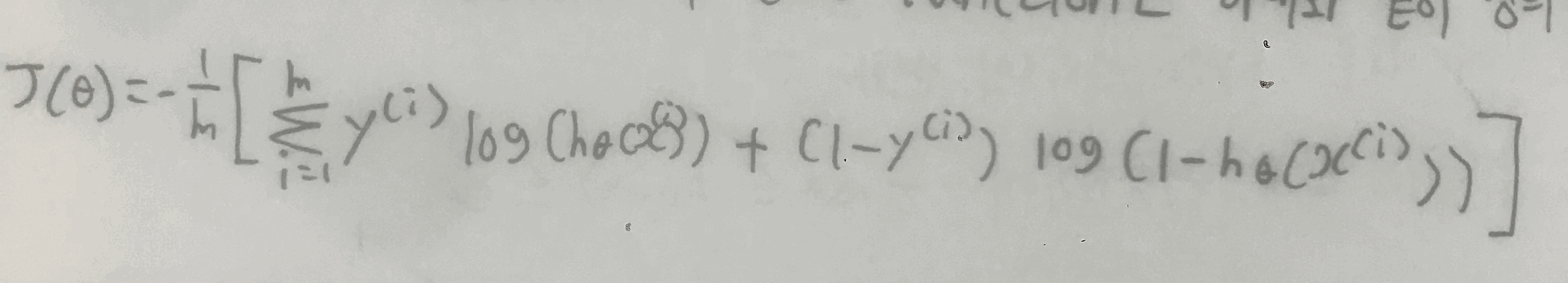
'자연어 처리 과정' 카테고리의 다른 글
| Overfitting과 underfitting 그리고 regularization (0) | 2022.12.01 |
|---|---|
| Softmax function and cross-entropy loss (0) | 2022.11.30 |
| Feature scaling에 대해 (0) | 2022.11.29 |
| 경사하강법 (0) | 2022.11.28 |
| determinant가 0이라는 것의 의미는? (0) | 2022.11.25 |



