개요
1. Seq2seq의 한계
2. Self-attention
3. Transformer의 탄생과 동작 과정 전 알아야 할 것
4. Transformer의 동작 과정
5. 마무리
Seq2seq의 한계
저번 글에서 다뤘던 것처럼 seq2seq는 Encoder-Decoder 구조를 가지고 있어서
RNN을 사용하여 번역 task를 처리할 수 있도록 도와준 구조이다.
그러나 제한된 차원을 가진 Context vector안에 encoder의 input sequence를 함축시켜야 한다는 문제점이 있었다.
그런 과정에 정보의 유실이 발생하는 건 크게 놀랍지 않은 일일 것이다.
이러한 seq2seq의 문제점을 attention mechanism으로 해소를 해낸 것이 seq2seq with attention이었다.
Self-attention
우리가 이전에 만났던 seq2seq with attention은 decoder with attention이라고 부를 수 있다고 했다.
그 이유는 decoder가 encoder의 정보에 attention을 하는 구조이기 때문이다.
즉, Query는 decoder의 각 time step의 hidden state 였고 Key-value는 encoder의 모든 time step의 hidden state였다.
표현하자면, Cross attention을 진행했던 구조인 것이다.
그렇다면 self-attention은 무엇일까.
표현에서 짐작할 수 있듯이, 자기 자신을 attention 한다는 것이다.
즉, Query = Key = Value인 것이 바로 self-attention인 것이다.
그럼 도대체 왜 self-attention이 필요하다는 목소리가 나왔을까?
왜 self-attention?

위는 구글 AI 블로그에 존재하는 사진이다.
영문을 해석해보면, "동물은 길을 건너지 않았다. 왜냐하면 그것은 너무나도 피곤했기 때문이다."이다.
이때, "그것"이라는 정보를 decoding 하기 위해 attention을 한다고 할 때,
input sequence 중에서 어떤 단어에 attention을 해야하는 걸까?
그건 바로 "animal"이겠지만, 컴퓨터는 이를 바로 알아내기 어려울 것이다.
결국, self-attention의 필요성은 여기에서 왔다.
self-attention은 문장 내에서 단어들끼리 attention을 함으로써 "그것"이 "동물"과 연관되어 있음을 나타낼 수 있는 것이다.
Transformer의 탄생과 동작 과정 전 알아야 할 것
탄생
위에서 설명한 self-attention을 seq2seq with attention 모델에 적용하고, RNN 구조를 아예 제거시킨 모델이 바로
Transformer이다.
seq2seq with attention과 self-attention이 붙여진 모델에서
Transformer는 RNN 구조를 제거하고 attention만으로 RNN을 대체한다.
즉, Transformer를 구성하는 요소를 간략하게 표현하면 아래와 같다.
1. Attention(+self-attention)
2. Fully connected
그리하여 이 모델을 소개한 논문의 이름은 Attention is all you need 이다.
동작 과정 전 알아야 할 것

본격적으로 Transformer가 흐르는 과정을 살펴보기 전에, 이번에는 좀 더 자세하게 Transformer를 구성하는 요소들을 알아보자.
(흐르는 순서대로 요소를 정렬한다.)
1. Embedding layer
2. Positional encoding
3. Multi-Head Attention(여러 개의 Scaled Dot-product attention, 결국 attention을 의미한다.)
4. Residual connection & Layer normalization
5. Position-wise feed forward fully connected
6. Linear transformation
7. Softmax
그리고 Self-attention이 진행되는 곳과 Cross attention이 진행되는 곳을 표시한 후 시작하려고 한다.
Cross는 Decoder-Encoder attention 즉, seq2seq에서 진행했던 attention이 진행된다.

Transformer의 동작 과정
Input embedding과 positional encoding
- input sequence를 embedding layer에 통과시키는 것부터 시작한다.
layer를 통과시키고 나면 차원은 d model이 된다. (논문 상에서는 d model은 512이다.)
* d model은 트랜스포머의 encoder와 decoder의 정해진 입력과 출력의 크기를 말한다. embedding vector의 차원도 이와 동일하며 각 encoder와 decoder가 다음 layer의 encoder와 decoder로 값을 보낼 때에도 이 차원을 유지한다.
그리고 embedding된 단어 vector는 positional encoding의 과정을 거친다.
이 과정은 매우 중요하다.
중요한 이유는 RNN이 쓰이지 않는 Transformer 구조에서 sequence data에게 순서 정보를 줄 수 있는 장치이기 때문이다.
그렇게 Positional encoding 과정을 거치면 우리의 단어 vector는 Transformer의 Encoder단으로 들어갈 준비를 마친다.
Positional encoding 과정까지 마친 우리의 input을 X라고 부르겠다.
Multi-head attention
- 이제는 attention이 진행되는 구간이다.
위에서 표시해놓은 것처럼 우리는 이 구간에서 Self-attention을 진행한다.
그리고 이름이 Multi-head attention인 이유는,
attention을 여러 겹을 쌓았기 때문에 multi인 것이고, 각각의 겹을 head라고 표현한다. 따라서 multi-head attention인 것이다.
겹겹이 쌓이는 attention은 정확히는 Scaled dot-product attention이다.
정리하자면, Scaled dot-product attention이 h겹만큼 쌓인 것을 Multi-head attention이라고 한다.
이제 그 흐름을 보자.

Positional encoding 과정을 거친 X는 Query, Key, Value로 만들어진다.
이 과정은 사진에 있는 Linear transformation 과정에서 이루어지는데 간단하다.
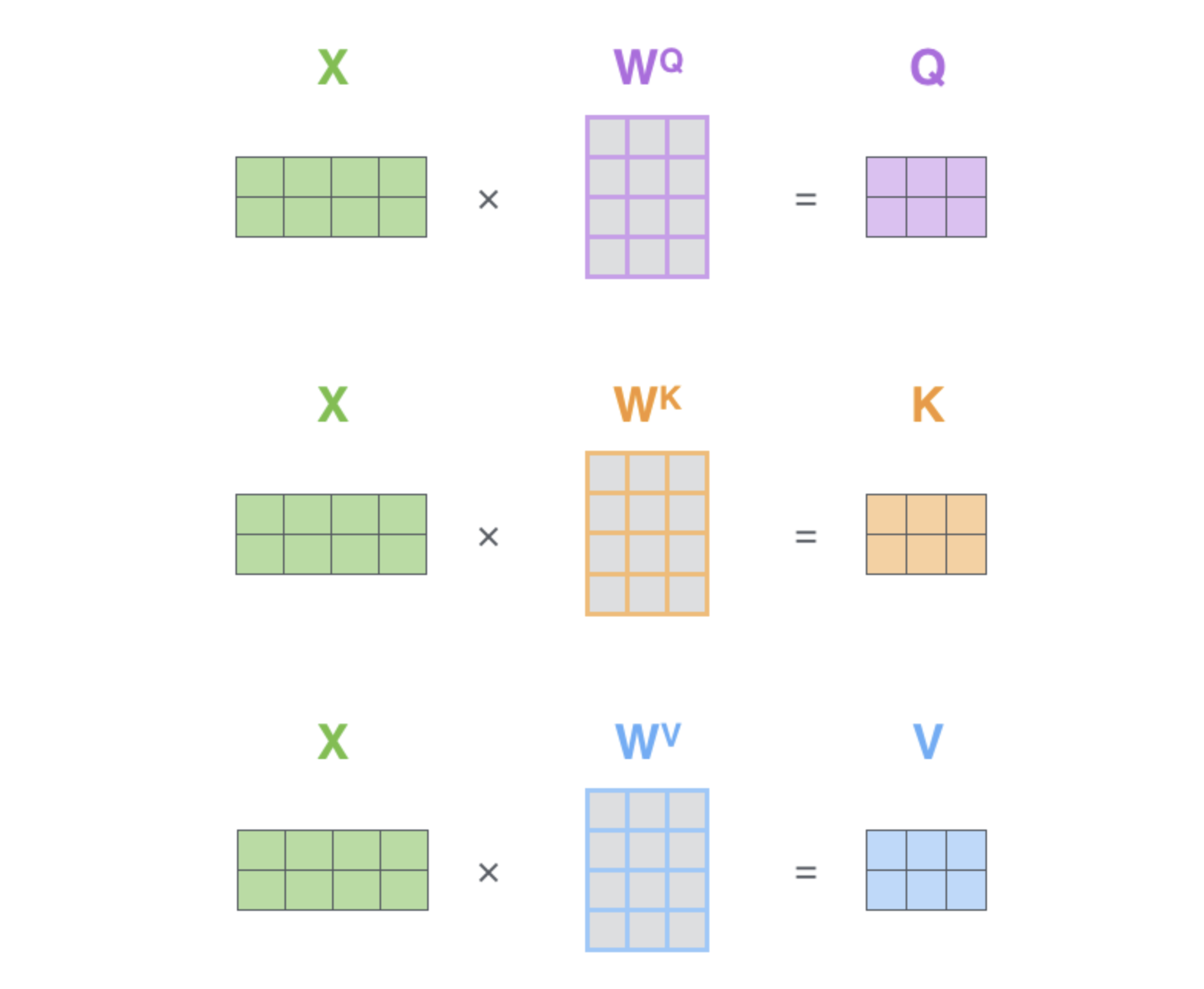
Linear transformation 과정에서 X가 각각 WQ, WK, WV와 만나 Q, K, V로 만들어지는 것이다.
그렇게 Q, K, V로 만들어진 값들은 아래 사진에서 확인할 수 있는 Scaled Dot-product의 내부 구조로 들어가게 된다.

Attention은 Query와 Key로 유사도가 구하고,
그 유사도에 Softmax를 통과시킨 Attention score를 Value에 가중합을 하는 것이라고 볼 수 있다.
(이 결과로 Attention value를 얻게 된다.)
과정을 보면 Query와 Key가 Matmul 즉, 내적을 하게 된다. 유사도를 구하는 것이다.
이 유사도를 우리는 1/K의 차원으로 scaling 해준다.
* 이때, 유사도 값을 1/K의 차원으로 scaling 해주는 이유는 softmax를 통과했을 때 attention 확률 값이 한 쪽으로 쏠리지 않게끔 하기 위함이다. 값이 한 쪽으로 쏠린다면 gradient 값이 작아질 가능성이 존재한다.
그렇게 유사도를 구했고, 그 값을 Scaling 해줬다.
이제 그 Scaling 해준 값을 Softmax에 통과시켜주면, 우리는 Attention score를 구한다.
그러므로 이제, Attention score를 Value에 가중합 해주면 된다! (V와 Matmul 후 Sum)
아래는 Scaled Dot-product Attention에서 일어나는 일을 한 번에 정리한 수식이다.

그렇게 구한 Attention value를 z라고 부르겠다.
그럼 그 z는 concat을 하게 되는데, 갑자기 웬 concat이냐?
위에서 언급했지만, 우리는 이 Scaled dot-product를 h번 쌓는다. 그래서 우리는 이를 Multi-head attention이라고 부른다.
우리가 구한 z를 첫 번째 head의 z라고 가정하자.
head가 8개라고 생각한다면, 우리는 총 8개의 z가 존재할 것이다. (z0 ~ z7)

그럼 이 8개의 z를 concat 해주는 것이다!
그리고 Linear layer를 거치게 되는데, 그 이유는 위의 사진에서 볼 수 있듯이 concat을 하면 차원이 너무 늘어나게 되기 때문에 parameter의 개수가 많아질 수밖에 없고, 그에 따라 연산량이 많아질 수밖에 없다.
따라서, 이를 조절해주기 위해 우리는 WO 가중치를 Linear layer에서 만나게 되고 이의 출력 차원은 d model과 같다.

이렇게 Multi-head attention이 마무리 된다.
Add & Norm
위의 Multi-head attention 과정이 마무리 되면 output으로 Z가 나타나게 될 것이다.
그 Z는 Add & Norm이라는 block으로 들어가게 된다.
* Add
우리는 Transformer 구조 사진에서 Add & Norm block으로 연결된 Residual Connection을 확인할 수 있다.
이 residual connection을 타고 넘어온 X(Positional encoding을 거친 값)이 Z의 차원과 d model로 같기 때문에 합이 가능하다.
그래서 이 둘을, X와 Z를 더해준다.
* Norm
그리고 더해준 값을 Layer normalization을 취해서 Layer 별로 zero-mean, unit-variance로 맞춰준다.
(alpha와 beta는 학습으로 구해진다.)
Feed-forward
그렇게 Add & Norm까지 마치면 우리는 Feed-forward sub-layer를 만나게 된다.
이 sub-layer의 정확한 이름은, Position-wise feed-forward fully connected sub-layer라고 한다.
그냥, feed-forward fully connected sub-layer와 크게 다를 것은 없다고 생각한다.
이 layer는 말 그대로 feed-forward로 fully connected layer를 거친다.
논문 상으로, 2개의 fully connected layer가 존재하며, 그 사이에 RELU가 배치되어 있다.
Masked Multi-head attention
오른쪽에 위치한 Decoder단을 보면 3개의 sub-layer가 존재하는데, output으로 들어가는 vector가 가장 먼저 만나게 되는 layer는 Masked Multi-head attention이다.
이때, output으로 들어가는 vector란 무엇이냐?
학습 시, teacher forcing을 했을 때 넣어줄 단어 vector인 것이다.
그럼 Masked란 이름은 왜 붙어있는 걸까?
그것은 바로 output으로 들어갈 단어 vector를 처리하는 데에 있어서 필요한 것이 masking이기 때문이다.
이게 무슨 말이냐?
우리의 target language가 <sos\> je suis étudiant라고 해보자.
우리의 Transformer 구조는 RNN 구조를 가지지 않는다. 그렇기 때문에 단어 vector가 input이 될 때, sequence별로 input 되는 것이 아니라 한 번에 모두 들어오게 된다.
그렇다는 말은, Decoder단에서 Attention을 할 때 정답을 보고 예측을 할 수가 있게 된다는 것이다.
그것을 막기 위해서 masking 과정이 필요했던 것이다.
이름은 어렵지만 과정은 간단하다.
Scaled dot-product attention에서 Q와 K로 유사도를 구하고 Scaling을 한 후에
현재까지 inference한 단어들을 제외한 모든 값을 zero-padding을 하는 것이다.

Masked Multi-head attention 이후
그렇게 decoder단에서 self-attention을 한 후, cross attention을 한다.
encoder단에서는 X가 WQ, WK, WV 가중치를 만나서 Q, K, V 역할을 했었는데
decoder단에서는 Masked multi-head attention을 통과한 값 Z가 WQ와 만나 Query가 된다.
그리고 맨 마지막 layer의 encoder output이
각각의 decoder의 multi-head attention sub-layer로 들어와서 WK, WV와 만나 Key Value가 된다.
(decoder의 multi-head attention에서)
Decoder의 Z -> Query
Encoder의 output -> Key, Value
그리고 feed-forward를 거치고 linear layer와 softmax를 거치면 output probability 가 완성된다.
마무리
이렇게 오늘은 개념적으로, 그리고 직관적으로 Transformer에 대해서 알아보았다.
각 sub-layer, layer마다의 자세한 기능은 추후에 올리려고 한다.
Reference
http://jalammar.github.io/illustrated-transformer/
'자연어 처리 과정' 카테고리의 다른 글
| What's the role of "pooler" in BERT? (0) | 2023.01.11 |
|---|---|
| BERT (0) | 2023.01.09 |
| What's the meaning of "Shifted right" in Transformer? (0) | 2023.01.05 |
| RNN with attention(seq2seq with attention) (0) | 2023.01.04 |
| Why do we need to add bias in neural networks? (0) | 2022.12.28 |


