개요
1. 초기 RNN의 번역 task
2. seq2seq의 등장
3. seq2seq with attention의 등장
4. 마무리
초기에 RNN을 어떻게 번역 task에 적용했을까?
word2vec모델 이후, 맥락을 고려할 수 있는 모델로 RNN이 등장했다.
이를 이용하여 기계 번역 task를 해결하기 위해 초기에는 통계 기반 번역인 SMT(Statistical Machine Translation)이 적용됐다.
하지만, SMT는 modeling을 할 때, feature engineering을 사람이 직접 해주어야 한다는 불편함이 존재했다.
이후, 이 문제를 해결한 딥러닝 기반 번역인 NMT(Neural Machine Translation)이 등장했고
사람의 손이 닿지 않아도 feature engineering을 처리해주었다.
그러나 번역 task에 있어서 우리에게는 핵심적인 문제가 있었다.
그것은 바로 input으로 들어가는 source language와 output으로 나오는 target language의 길이가 맞지 않는다는 것이었다.
그리고 input과 output의 길이가 정해져 있지도 않기에, 이를 처리하는 것이 크나큰 문제였다.
Seq2seq의 등장


input과 output의 길이를 제한하는 데에 있어서 문제를 겪었으나, 그 문제를 해결해준 모델이 바로 Seq2seq이다.
Seq2seq는 도대체 어떤 과정으로 sequence를 처리하기에 위와 같은 문제를 해결할 수 있었을까?
과정에 대해 이야기하기 전, Seq2seq의 핵심은 Encoder-Decoder 구조, Context vector라고 말할 수 있을 것이다.
Seq2seq의 sequence 처리 과정
(Encoder)
1. 먼저 Encoder단에서 기존 RNN과 마찬가지로 sequence data를 embedding layer에 input한다.
이때, RNN과 다른 점은 hidden state를 위로 흘리는 동작이 없으며 inference를 하지 않는다는 점이다.
inference를 하지 않고, hidden state vector만을 다음 time step으로 흘려준다.
2. 그렇다면 RNN의 기본 구조에서 나타나는 것과 마찬가지로, 맨 마지막 time step의 hidden state vector가 나타나게 될 것이다.
그리고 그 hidden state vector는 그전의 time step의 정보들을 함축하고 있는 vector일 것이다.
즉, input sequence의 정보를 담고 있는 vector라는 것이다.
* 이렇게 Encoder가 맨 마지막에 내뱉은 hidden state vector가 바로 Context vector의 역할을 한다.
이 Context vector는 input sequence의 정보를 담고 있어서 Decoder는 이 Context vector에 담긴 정보를 보고
번역 task를 해내는 것이다.
즉, input과 output의 길이는 상관 없이
Encoder-Decoder 구조를 통해 Context vector로 input sequence의 정보를 전달할 수 있게 된 것이다.
(Decoder)
3. 그렇게 Encoder에서 건네준 Context vector를 받게 된다.
이제는 정말 기본 RNN과 동작이 같다고 볼 수 있다.
4. Context vector를 h0이라고 보고, start token을 xt라고 보면 우리는 LSTM cell을 통해 output과 hidden state를 얻을 수 있다.
즉, RNN의 흐름과 동일하며 output을 softmax에 통과시켜 예측 단어를 얻을 수 있다. 그리고 그 예측 단어가 다음 time step의 xt가 되는 것이다.
(학습 시에는 teacher forcing한 단어가 decoder 부분에서 input으로 들어갈 수도 있다.)
Seq2seq의 한계점
이렇게 완벽해 보이는 seq2seq 모델에도 한계점은 존재했다.
그것은 바로 Context vector에 있었다.
우리의 input sequence가 매우 길다고 가정해보자.
Context vector는 즉, hidden state vector였기에 차원이 정해져 있다.
다시 상기시켜 보면, 우리는 Context vector에 input sequence의 모든 정보를 함축해놓아야 한다.
그러니까, 우리는 정해진 차원을 가진 Context vector 안에 우리의 input sequence의 정보를 어떻게든 넣어야 한다는 말이다.
그렇다면 input sequence의 정보가 모두 정상적으로 담길 수 있을까?
우리가 가정했던 긴 sequence가 input으로 들어온다면, 정해진 차원에서 input의 정보를 충분히 표현하기는 힘들 것이다.
정리하자면, Context vector가 Decoder로 input sequence의 정보를 잘 넘겨주어야 하는데
그러지 못할 가능성이 존재한다는 것이다.
그렇다면 우리는 어떻게 이 문제를 해결해야 할까?
Seq2seq with attention의 등장
우선, 여기서 소개할 seq2seq with attention 모델은 decoder with attetion이라고도 할 수 있으며
쓰이는 attetion mechanism은 Dot-product attetion이다.
seq2seq with attetion 모델의 Encoder단(Bi-directional)

seq2seq with attetion 모델의 Decoder단(Bi-directional X)
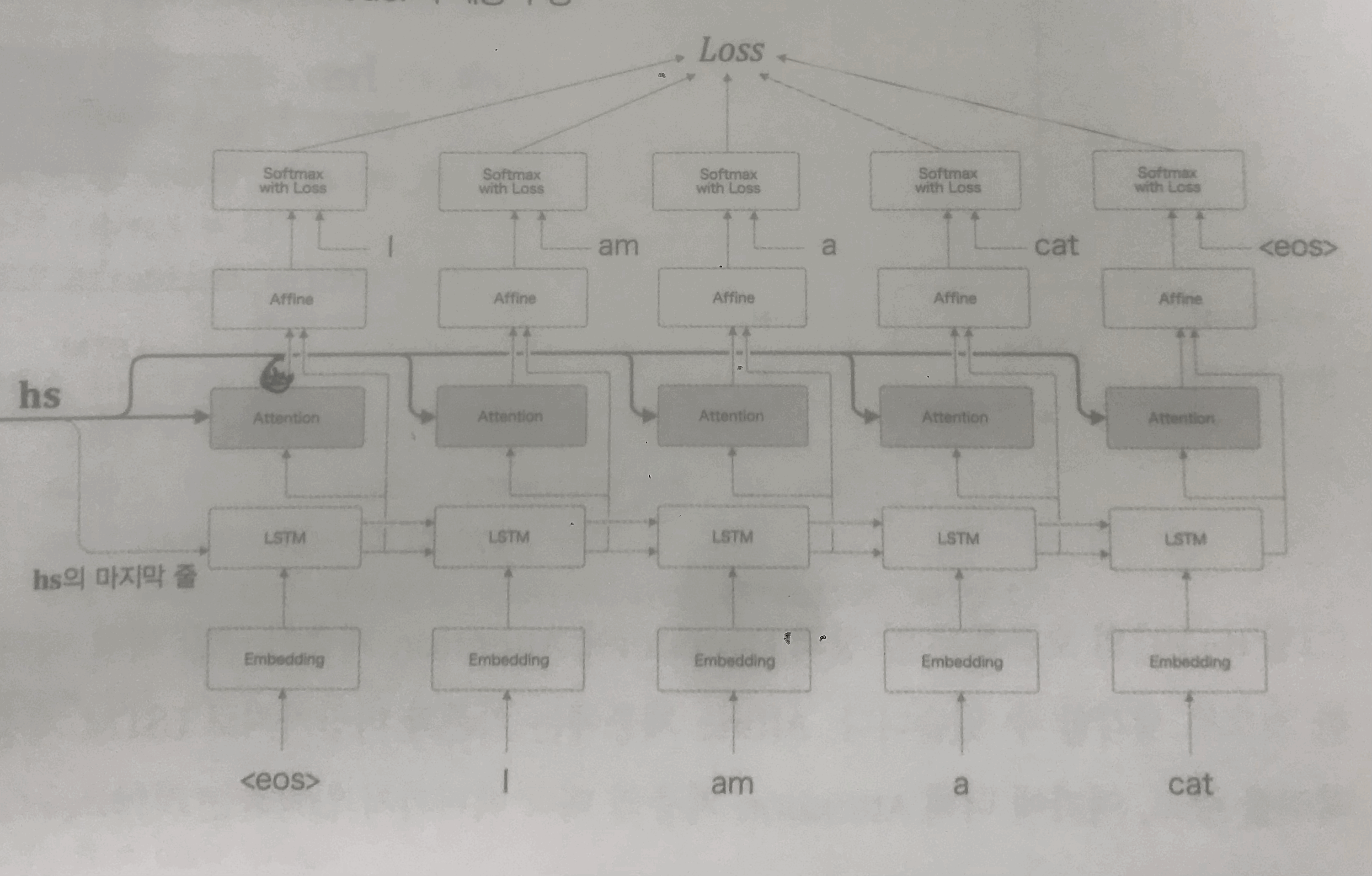
seq2seq with attetion 모델의 Encoder와 Decoder를 같이 바라본 모습(Dot-product attention)
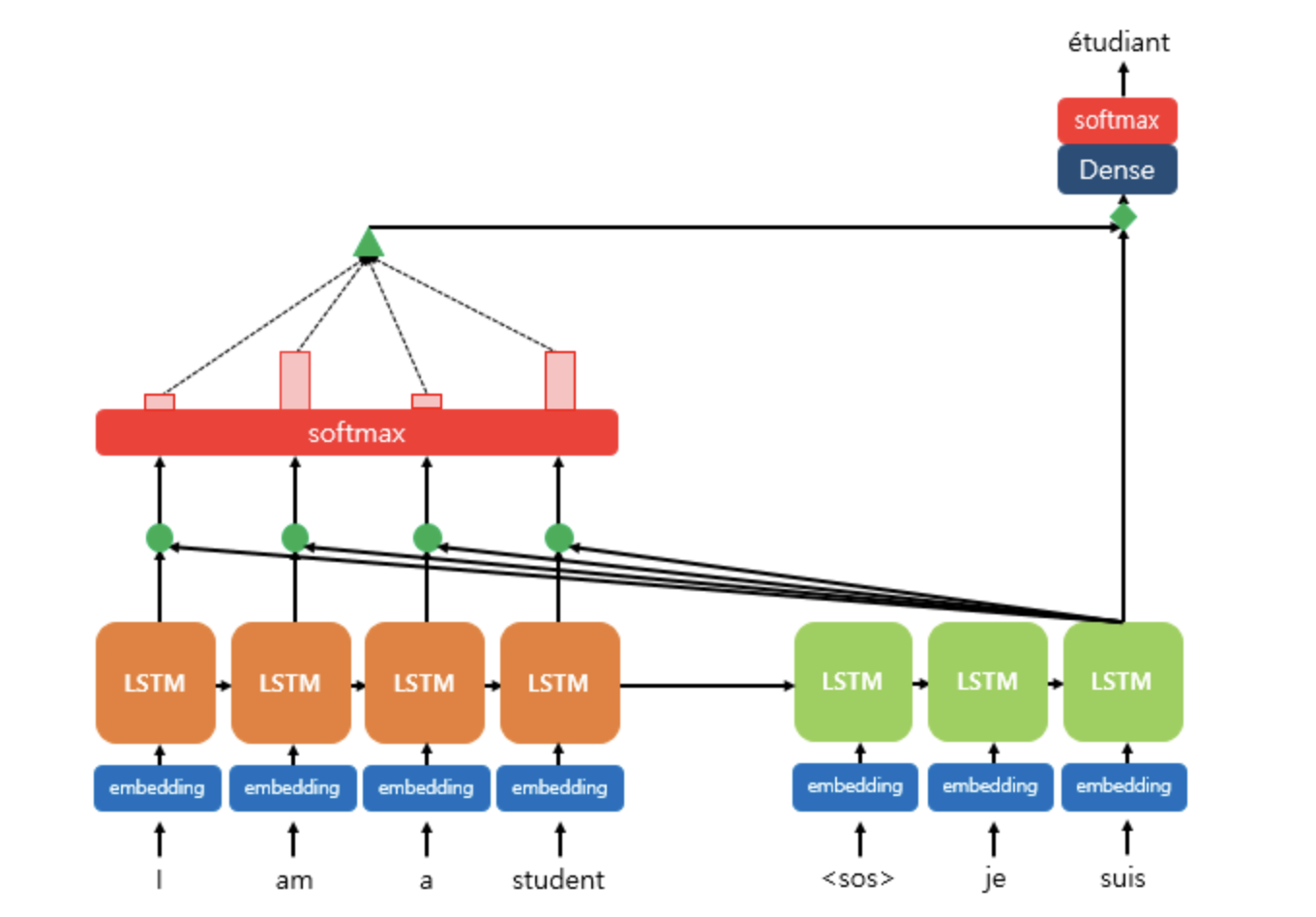
먼저, Bi-directional RNN에 대해 언급을 해야 할 것 같다.
Encoder 부분을 보면 갑자기 LSTM cell이 forward 방향, backward 방향으로 생겨났다.
이는 양쪽으로 LSTM cell을 설치하여 편향된 방향으로만 맥락을 바라보지 않고 양방향으로 맥락을 바라볼 수 있도록 도와주는 구조이다.
지금은 bi-directional을 설치하지 않은 seq2seq with attetion 모델을 말하려고 하므로 backward의 LSTM cell은 없다고 보면 된다.
새로운 용어가 나타났으나, 설명에는 쓰지 않았다.
Q = Query : t 시점의 디코더 셀에서의 은닉 상태 -> dh로 표현했다.
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들 -> hs로 표현했다.
V = Values : 모든 시점의 인코더 셀의 은닉 상태들 -> hs로 표현했다.
Attetion mechanism은 어떻게 제한된 차원에서 정보를 전달하는 문제를 해결하였나?
다시 본론으로 넘어오자.
seq2seq with attetion 모델은 제한된 차원의 context vector로 인해 정보를 잘 전달하지 못하는 문제를 해결했다.
이는 seq2seq with attetion 모델이 동작하는 흐름을 보면서 이해해보자.
Encoder단에서의 seq2seq with attention의 동작 과정
seq2seq 모델에서 encoder단이 동작했던 것과 조금 다르다.
1. 우선, seq2seq에서와 마찬가지로 input sequence를 embedding layer에 input 해주고, LSTM cell로 input 한다.
2. 기존 seq2seq 모델에서와는 달리 그리고 기존 RNN 모델과 같이
output은 위로 보내주고 hidden state를 다음 time step에 흘려보내준다.
이때, 우리는 각 time step에 output이 존재할 것이며
마지막 time step의 hidden state vector가 input sequence의 정보를 담고 있음을 알고 있다.
* output을 신경 쓴다는 것이 seq2seq with attetion 모델의 차별점인데, 이것이 바로 핵심이다.
seq2seq with attention은 기존 seq2seq 모델과는 달리 Context vector만을 활용하는 것이 아니라
Encoder의 output까지 Decoder가 활용할 수 있도록 하는 것이다.
즉, Decoder는 Context vector뿐만 아니라
Encoder의 output을 모두 stack해둔 hs까지 활용하여 inference를 할 수 있게 됐다.
Decoder단에서의 seq2seq with attention의 동작 과정
위에서 seq2seq with attention을 소개하기 전에, 이 모델을 decoder with attention이라고 말할 수도 있다고 언급했다.
그 이유는 바로, 이 모델에서는 decoder 단에서만 attention mechanism이 쓰이기 때문이다.
Encoder단에서 정보를 전달해주는 것에서부터 어느 정도 기존 Context vector의 문제점을 해소하였다고 볼 수 있다.
그렇다면, Attention mechanism은 어떻게 번역 task에 성능 향상에 도움을 준다는 것인가?
그리고 Encoder의 output인 hs는 어떻게 쓰이는 것일까?
이것도 마찬가지로, 동작 과정을 보면서 이해해보자.
1. Decoder로 넘어온 정보는 2가지이다. Encoder의 output인 hs와 마지막 hidden state vector 즉, Context vector이다.
Context vector는 기존 seq2seq와 마찬가지로 같은 역할을 한다.
맨 처음 decoder의 input으로 들어올 start token과 context vector가 RNN cell의 input으로 들어가서
decoder단에서 나타나는 첫 hidden state vector를 만들어 낼 것이다. 이를 dh라고 부르겠다.
2. decoder단에서 만들어낸 첫 hidden state vector인 dh는 기존의 RNN cell의 흐름과 마찬가지로 다음 time step으로 넘어갈 것이며, copy 되어 위로 흐를 것이다.
3. 그 위로 흘러간 dh는 사진에서 볼 수 있는 것처럼 Attention block으로 들어가게 된다.
Attention block 안에서는 3가지 일이 일어난다.
(1) dh와 hs의 내적 -> Similarity
(2) Similarity를 Softmax -> Attention score(Attention weight)
(3) Attention score와 hs의 가중합 -> Attention value

Similarity?
우리는 decoder with attention을 보고 있는 것과 같다, 그리고 사진(같이 바라본 모습)에서 볼 수 있는 것처럼 decoder가 encoder를 바라보고 있는(attention) 모습을 볼 수 있다.
즉, similarity를 구한다는 것은 Decoder가 다음 time step의 output을 내뱉을 때,
Encoder의 output 중 어느 부분을 attention 하여 state를 생성해야 하는 것인지 hs 중에서 선택하는 과정이라고 볼 수 있다!
Attention score?
그 값을 softmax를 통과시키면 0~1의 값으로 도출이 될 것이며,
그것이 어느 정도로 attention을 해야 하는 건지 알려주는 Attention score인 것이다.
Attention value?
어떤 정보에 attention을 해야 하는지 알 수 있는 Attention score를 구했으니 우리는 이것을 hs에 element wise로 곱해주고
그 값들을 모두 더해주면, Decoder가 attention하길 원했던 정보를 갖게 되는 것과 같은 것이다!
4. 이렇게 구한 Attention value와 dh를 Affine layer 즉, bias가 존재하는 fully connected layer에 통과시키고
softmax를 통과시킨다.
5. 그럼, 결과적으로 inference한 단어를 얻을 수 있는 것이다!
그리고 RNN의 흐름을 그대로 따라, 그 inference한 단어는 다음 time step의 input으로 들어가게 될 것이다.
(마찬가지로, 학습 시 teacher forcing을 한다면 Ground truth가 들어갈 수도 있다.)
마무리
이렇게 번역 task를 위한 Seq2seq의 등장에서부터 seq2seq with attention 모델까지 알아보았다.
seq2seq with attention 모델이 나타나면서는 encoder에 attention을 설치할 필요가 있다는 목소리가 커졌고
그렇게 self-attention이 등장했고, Transformer가 등장했다.
attention에는 다양한 mechanism들이 적용될 수 있다.
오늘 소개한 Luong의 Dot-product Attention부터 Bahdanau의 concat attention등이 있다.
Reference
https://velog.io/@guide333/Attention-정리
https://heung-bae-lee.github.io/2020/01/21/deep_learning_10/
'자연어 처리 과정' 카테고리의 다른 글
| Transformer - overview (1) | 2023.01.06 |
|---|---|
| What's the meaning of "Shifted right" in Transformer? (0) | 2023.01.05 |
| Why do we need to add bias in neural networks? (0) | 2022.12.28 |
| Why RNN share the same weights? (0) | 2022.12.28 |
| Word2vec vs GloVe (0) | 2022.12.27 |

