개요
자연어 처리에서 사용될 수 있는 neural network인 RNN에 대해 알아보자.
RNN?
RNN은 Recurrent neural network를 의미하는 말이다.
즉, 한국말로 바꿔서 표현해보면 순환 신경망 정도로 표현해볼 수 있다.
이 RNN은 text 같은 sequential 데이터와 시계열 데이터를 다룰 수 있는 신경망이다.
이 RNN이라는 신경망은 도대체 어떻게 생겼으며, 어떻게 자연어 처리를 할 수가 있는 걸까?
RNN의 구조


위의 사진 기준으로 보자면
핑크색 노드가 input
초록색 노드가 hidden
파란색 노드가 output이다.
도대체 뭐가 어떻게 흐르는 걸까?
forward, backward propagation이 어떻게 진행이 되는 걸까?
RNN의 forward propagation

그림으로 보자면 바로 이런 식으로 forward propagation이 진행된다.
초록색 노드 즉, hidden node에서 발생하는 값을 hidden state vector라고 표현할 수 있는데 이 값을 h라고 하겠다.
그럼 현재의 시간을 t라고 하면, 현재의 hidden state vector를 만들기 위한 입력은 어떻게 될까?
그것은 바로 이전의 hidden state vector인 ht-1 + 현재의 input xt가 되는 것이다.
현재의 hidden state를 만들기 위한 더 자세한 식은 아래에서 확인할 수 있다.
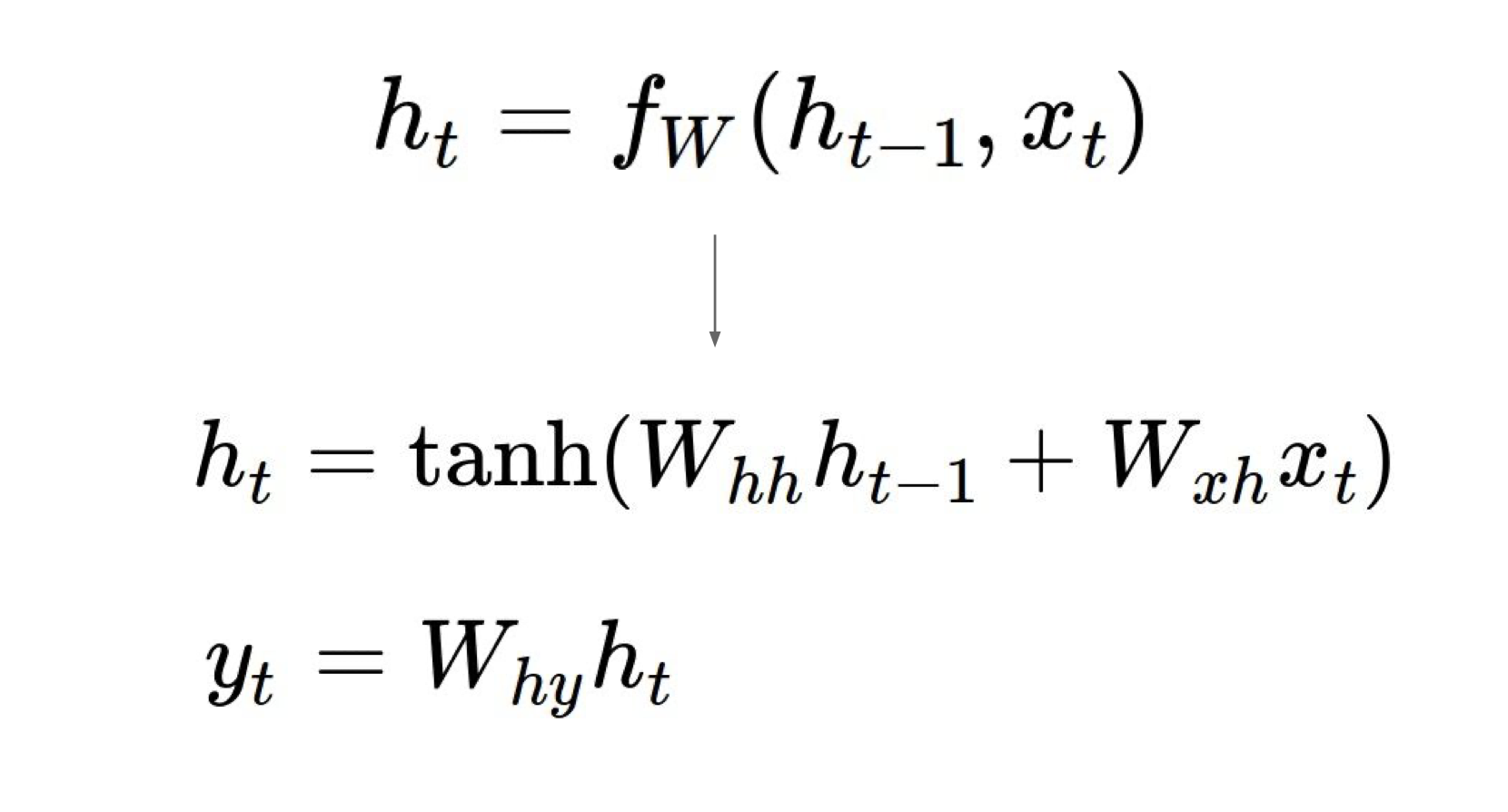
hidden state 값을 만들어주기 위해 우리는 이전의 hidden state의 선형 결합 값과 현재의 input x의 선형 결합 값을 더하고
그 더한 값을 tanh activation function에 통과시켜주면 된다.
왜 하필 tanh activation function을 사용할까?
1. RNN은 zero-centered 문제가 중요하다.
아래에서 설명을 하겠지만, RNN 모델은 gradient exploding, vanishing 문제가 심각하기 때문에
값이 zero-centered 하지 못하면 결국 gradient를 곱해준 값이 exploding 되거나 vanishing 되어 정보가 소멸될 수 있다!
2. tanh는 normalization 효과를 내준다.
사실 RNN은 위에서 설명했던 구조적 특징을 제외하면 Fully connected와 비슷한데
이 말은 곧, 값을 적당한 범위로 조절해줄 수 있는 무언가가 필요하다는 말이다.
그런데 tanh는 비선형성을 제공해주면서도 output 값의 범위가 -1~1이기 때문에 normalization 효과를 볼 수 있도록 해준다.
근데 왜 순환 신경망일까?
그 이유는 바로 RNN은 같은 parameter를 공유하기 때문이다.
더 자세히 말하자면, 같은 목적지의 노드로 향하는 간선에 있는 가중치끼리 같은 값을 가지고 있다.
사진에서 간선들의 색이 다른 것을 확인할 수 있는데, 같은 색끼리는 가중치가 모두 같다.
이렇게 가중치가 모두 같음으로써 효율성, 정보를 유지하는 데에 도움을 줄 수 있다.
어떻게 정보를 유지하는 데에 있어서 도움을 줄까?
backpropagation을 하는데 가중치가 모두 같으므로 그냥 제곱을 벗겨나가는 식으로 진행을 하면 되기 때문이다.
그럼 backpropagation은 어떻게 진행될까?
RNN의 Backpropagation

위에 사진에 그려진 화살표의 흐름대로 backpropagation이 진행된다.
저렇게 gradient 값이 전달되면서 결국 변화된 가중치 값에 따라 각 시간대의 데이터의 y에도 영향을 주게 된다.
따라서, 모든 값들이 영향을 받게 된다고 볼 수 있다.
왜?
모두가 연결되어 있는 구조이기 때문이다!
loss값에 따른 backpropagation이 이뤄지고 gradient에 따라 가중치가 업데이트 되면
각 hidden state와 y는 새로운 값을 가지게 되고
또 각 hidden state가 새로운 값을 가지게 된다는 말은 다음 타임 step의 hidden state에도 영향을 준다는 의미가 된다.
아래와 같은 모양새이다!

RNN의 단점
Gradient exploding, vanishing
만약 RNN의 구조가 아래처럼 커진다면 backpropagation 과정에서 gradient는 어떻게 될까?

또 이 위의 구조보다 더 커진다면 gradient는 어떻게 될까?
Q. 만약, 가중치가 절대값 1보다 크다면?
backprop시 계속 값이 제곱되면서 gradient 값이 미친듯이 커져 결국 발산하게 될 것이다.
-> gradient exploding
Q. 만약, 가중치가 절대값 1보다 작다면?
backprop시 계속 값이 줄어들면서 gradient 값이 0으로 수렴하게 될 것이다.
-> gradient vanishing
이렇게 gradient가 정상적으로 전달되지 못하면 도대체 어떤 문제가 생기길래?
-> 너무나도 중요한 sequential 정보가 소멸되어 버린다.
즉, 데이터가 소멸되어 버리기 때문에 모델이 예측을 할 수가 없게 되어버린다.
이러한 문제를 Memory dependency라고 부른다.


