개요
RNN의 내부 구조를 변경한 RNN인 LSTM을 알아보자.
그리고 LSTM 구조가 어떻게 기존 RNN의 문제였던
Memory dependency(gradient 값을 제대로 전달해줄 수 없어서 생기는 문제)를 보완하였는지 알아보자.
기존의 RNN은 어땠나?

Vanilla RNN은 위와 같은 형태의 구조를 지녔다.
이전 타임 스텝의 hidden state와 현재의 input x가 더해지고 이 값이 tanh를 통과하면
현재의 hidden state 값이 만들어졌다.
그리고 이 hidden state가 또 다음 타임 스텝의 입력에 영향을 주게 되었다.
LSTM RNN 역시 기본적인 틀은 유지하고 있다.
하지만 vanilla RNN에서 문제가 되었던 gradient 값의 전달을 원활하게 해줄 수 있는 구조를 가지고 있다.
LSTM의 구조
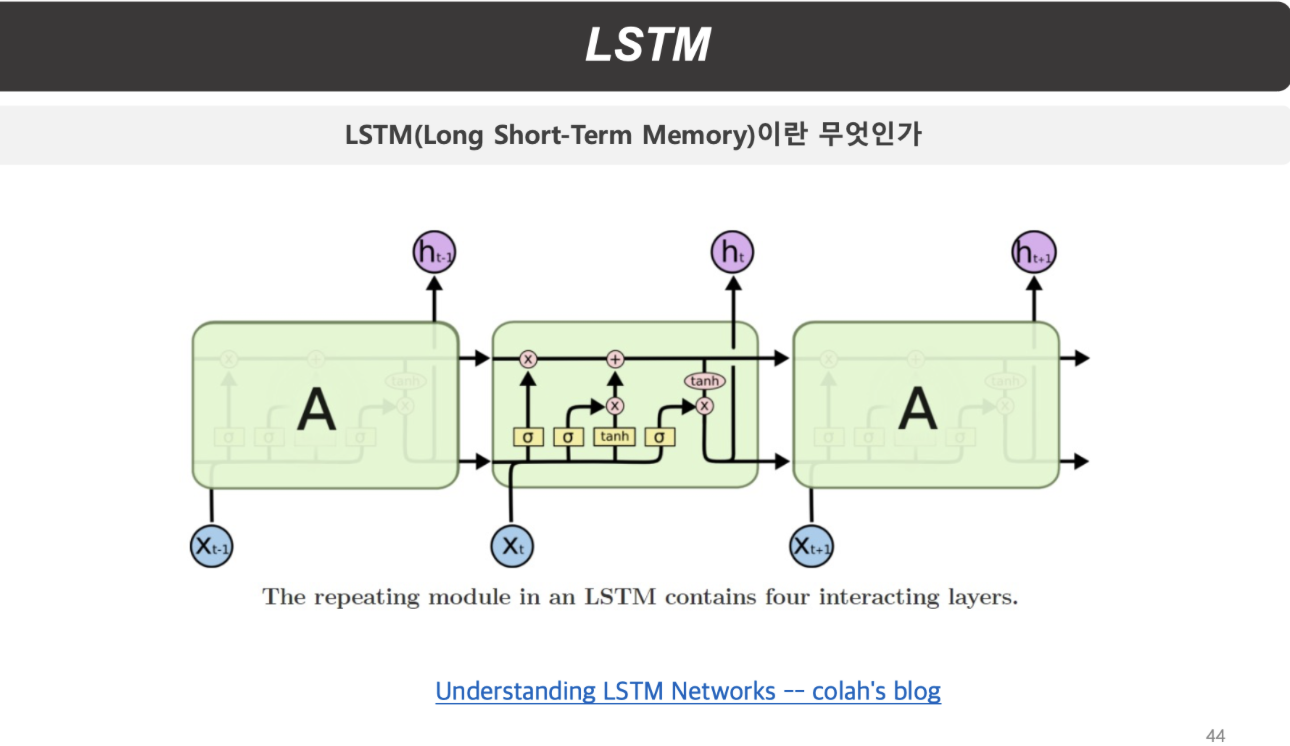
확실히 vanilla RNN과 비교했을 때 복잡해진 내부 구조를 가지고 있음을 확인할 수 있다.
저 내부 구조에 들어가보면 아래와 같은 모습을 하고 있다.

vanilla와 RNN과 똑같이 LSTM RNN도 같은 가중치를 가지고 있다.
하지만 LSTM에서는 이전 타임 스텝의 hidden state 값 ht-1과 현재의 input xt가 결합한 값이 다양한 방법으로 사용된다.
일단 LSTM에는 4가지의 gate가 존재하고, 2개의 path가 존재한다.
2개의 path는
1. cell state(memory의 역할)
2. hidden state
4개의 gate는
1. forget gate
2. input gate
3. gate gate
4. output gate
즉, cell path가 과거의 cell state 값을 계속 보존해주기 때문에 backprop이 일어나도 gradient가 계속해서 보존이 될 가능성이 높아지는 것이다.
두 번째인 hidden state는 역할이 vanilla RNN과 같다.
4가지 gate에 대한 설명을 하기 전에, gate에 해당하는 값들이 어떻게 구성되는지 알아보자.
사진에서 볼 수 있는 것처럼 W와 ht-1 그리고 xt가 결합한 값에 sigmoid와 tanh를 통과시켜주는 것이다.
이때, W는 어떻게 4개의 세트를 이루고 있냐?
Wf, Wi, Wg, Wo
즉, 각 gate에 맞는 가중치 W 4개가 stack이 쌓인 형태인 것이다.
그래서 이렇게 결합된 값들 중
한 세트가 sigmoid를 통과해서 forget gate의 값이 되고
한 세트가 sigmoid를 통과해서 input gate의 값이 되고
한 세트가 tanh를 통과해서 gate gate의 값이 되고
한 세트가 sigmoid를 통과해서 output gate의 값이 되는 것이다.
Gate의 역할이 뭘까?
이 그림을 다시 한번 보자.
맨 왼쪽부터 노란색 박스가 네 개 있는데 순서대로, forget gate, input gate, gate gate, output gate이다.
각각의 gate의 역할을 살펴보자.
Forget gate
이전의 타임 스텝에서 cell path를 통해 흘러들어온 이전의 cell state 값을 현재에서 받을 때 얼마나 지워줄 것이냐 대한 gate이다.
우리가 앞에서 ht-1과 xt 그리고 W를 결합한 값을 sigmoid에 통과시켰기 때문에 최종 output인 f의 값은 0~1 사이이다.
그래서 이 f 값이 0에 가까울수록 이전의 cell state 값을 지울 것이라는 거고,
f 값이 1에 가까울수록 이전의 cell state 값을 보존할 것이라는 거다.
이 forget gate를 통과하면 뒤의 +쪽으로 cell state 값이 흐른다.
Input gate, Gate gate
우선 Input gate는 forget gate와 마찬가지로 sigmoid를 통과했기 때문에 %를 나타내주는데 어떤 %를 나타내주느냐?
현재 hidden state 값을 지금 cell path에서 흐르고 있는 cell state 값에 얼마나 드러내줄 것인지에 대한 %를 나타내는 역할을 한다.
그래서 즉, Gate gate의 값은 cell state 값에 더해질 candidate 값이다.
결국 input gate의 값과 gate gate의 값을 곱한 결과를 위로 올려주면
흘러오던 cell state 값에 현재의 candidate 값이 더해지면서 현재의 cell state 값이 되는 것이다.
그리고 그 cell state 값은 다음 타임 스텝으로 흐른다!
Output gate
Input gate와 gate gate가 만든 값이 cell state에 더해지면서 tanh가 있는 쪽으로 cell state 값이 흘러오게 된다.
이때, 다 만들어진 cell state 값은 tanh가 있는 길목에서 copy된다.
즉, 다 만들어진 cell state 값 하나는 다음 타임 스텝으로 흐르고
복사된 cell state 값 하나는 tanh가 있는 쪽으로 흐른다.
그래서 cell state 값은 tanh를 통과하여 값의 범위가 -inf ~ inf에서 -1 ~ 1로 변하게 된다.
이 값과 output gate가 곱해지는데
이 output gate 역시 sigmoid를 통과했기 때문에 %의 역할을 한다.
즉, cell state의 값 중 얼마를 현재의 hidden state 값으로 만들어서
다음 타임 스텝의 hidden state 값으로 보내줄 것이냐를 결정하는 역할이 바로 output gate인 것이다!
그럼 이제 도대체 이 복잡한 구조에서 forward, backward propagation이 어떻게 진행되는지 알아보자.
그러면서 어떻게 vanilla RNN의 문제였던 gradient 문제를 해소할 수 있었는지 알아보자.
LSTM의 forward propagation
복잡한 것 없이 forward prop은 위의 사진의 화살표 방향 그대로 흐른다.
LSTM의 backward propagation
우선, gradient 값은 화살표로 연결된 모든 곳으로 흐른다.
일단 cell path, 즉 highway부터 살펴보자.

highway는 이런 식으로 흐르는데, 정말 저렇게 화살표가 있는 저대로만 영향을 받는 게 아니다.
cell state가 back prop을 하면서 영향을 받는 값은
1. hidden state가 tanh를 통과하여 올라온 gradient 값
2. forget gate 값
그리고 cell path는 backprop할 때 사실 저렇게 두 갈래로 나눠서 흘러가는 식이라는 걸 인지해야 한다.
즉, 위쪽은 1, 2번 값만 영향을 받는 highway이고
아래쪽 길은 모든 path로 gradient를 전달한다.
여기서 언급한 highway 때문에 우리는 vanilla RNN의 gradient 문제를 해소할 수 있었다.
왜?
forget gate 값이 0만 아니라면 gradient 값은 다양한 forget gate 값과 곱해지면서 계속 보존이 될 수밖에 없기 때문에
대신, forget gate값이 모두 0이면 gradient vanishing 문제가 발생한다.
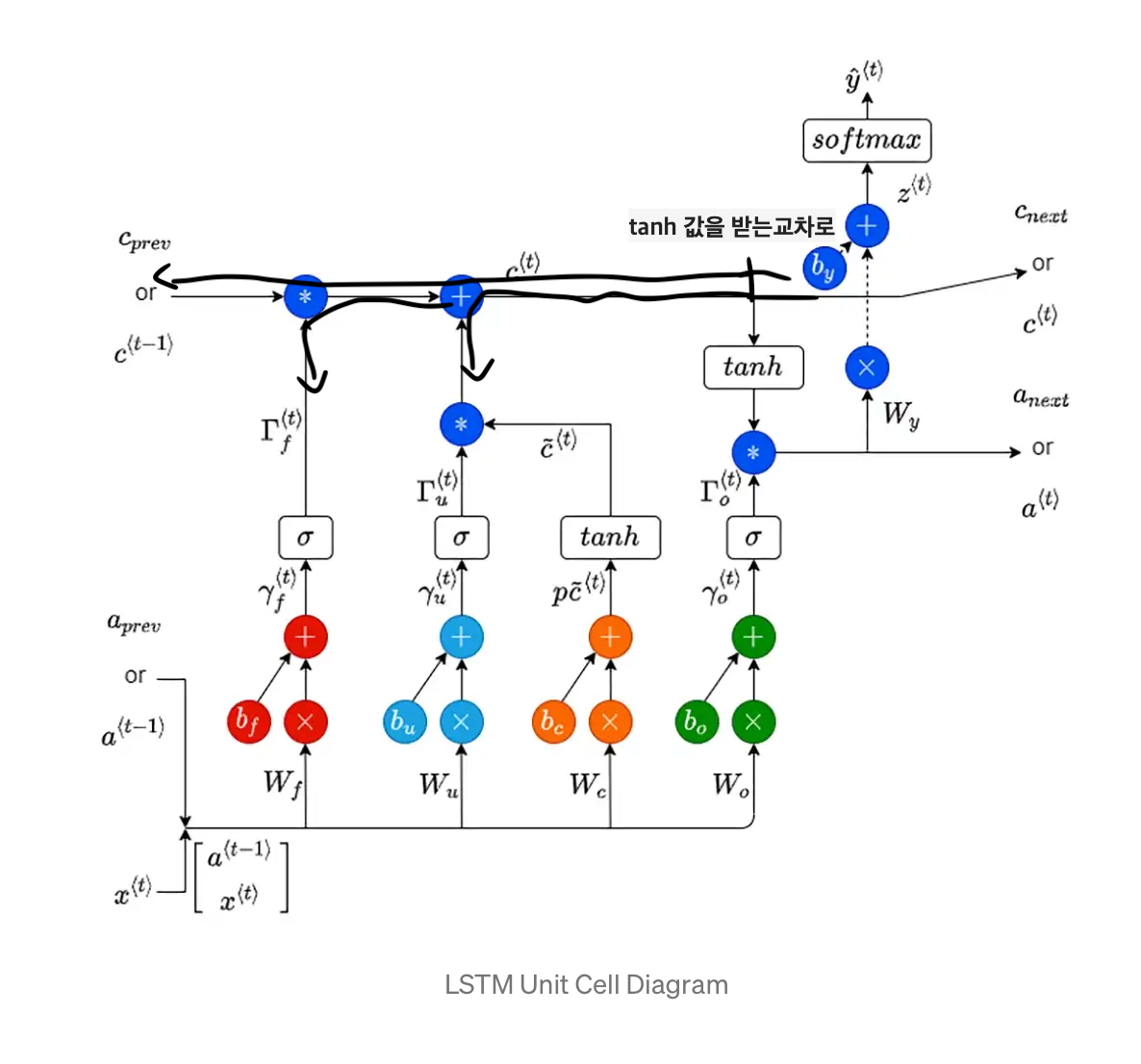
이러한 LSTM의 구조로 gradient를 vanilla 버전에서보다 더 길게 보존할 수 있게 되었고
그만큼 정보에 대한 memory가 길어져서 학습을 더 잘할 수 있게 되었으며, 그만큼 모델의 성능이 좋아지게 되었다.
'자연어 처리 과정' 카테고리의 다른 글
| Word2vec vs GloVe (0) | 2022.12.27 |
|---|---|
| Time sequence로 정렬하기 (0) | 2022.12.21 |
| RNN (0) | 2022.12.18 |
| VGG (0) | 2022.12.18 |
| CNN의 연산 (0) | 2022.12.18 |

